Categorical and item/response data clustering with the Latent Class Analysis
Source:vignettes/LCA.Rmd
LCA.RmdLoads the necessary packages for the vignettes.
library(future) # allows parralel processing in greed()
library(greed)
library(aricode) # for ari computation
library(dplyr) # data wrangling
library(tidyr)
library(purrr)
library(ggpubr) # advanced ploting
library(ggplot2)
library(ggwordcloud)
library(careless) # survey pre-processing
set.seed(2134)
future::plan("multisession", workers=5) # may be increased The greed package and DLVM framework allows the
clustering of categorical data. This vignette describes typical use
cases of the greed() function in this context, and
illustrates its use on real datasets.
The model
We are interested in the clustering of categorical datasets, which are typically found in survey data or item response theory (ITR). In this context, we observe \(n\) individuals described by \(p\) variables, taking one among \(d_j\) modalities for each variable \(j\). Such datasets are typically represented using a one-hot-encoding of each factor in a design matrix \(\mathbf{X} \in \{0,1\}^{n \times d}\) where \(d = \sum_{j=1}^p d_j\). Latent class analysis (LCA) is a generative model for categorical data clustering which posits conditional independence of the factor variables conditionally on the (unknown) partition. Below is a description of its Bayesian formulation with the use of proper conjugate priors \[ \begin{equation} \begin{aligned} \pi&\sim \textrm{Dirichlet}(\alpha),\\ \forall k, \forall j, \quad \theta_{kj} &\sim \textrm{Dirichlet}_{d_j}(\beta), \\ Z_i&\sim \mathcal{M}_K(1,\pi),\\ \forall j=1, \ldots, p, \quad X_{ij}|Z_{ik}=1 &\sim \mathcal{M}_{d_j}(1, \theta_{kj}),\\ \end{aligned} \end{equation} \] For each cluster \(k\) and variable \(j\), the vector \(\theta_{kj}\) represents the probability of each of the \(d_j\) modalities. With the above choice of priors, the LCA model admits an exact ICL expression similar to the mixture of multinomials derived in the supplementary materials of Côme et. al. (2021, Section 3) .
The greed package implements this model via the
Lca model-class and the default values for hyper-parameters
are set as follows:
- \(\alpha\) is set to 1
- \(\beta\) is set to 1, defaulting to an uninformative uniform prior on \(\theta_{kj}\)
This default values may be changed and we refer to the
?Lca documentation for further details.
Analysis of two real datasets
We now illustrate the use of the greed package on two
real datasets:
- Mushroom data from UCI Machine Learning Repository describing 8124 mushrooms with 22 phenotype variables. Each mushroom is classified as “edible” or “poisonous” and the goal is to recover the mushroom class from its phenotype.
- Young people survey data from Miroslav Sabo and available on the Kaggle platform. This is an authentic example of questionnaire data where Slovakian young people (15-30 years old) were asked musical preferences according to different genres (rock, hip-hop, classical, etc.).
These two datasets come attached with greed package.
Mushroom data
data("mushroom")We begin by forming the necessary vectors for analysis. The data has \(n=8124\) rows and \(p=23\) columns. The first column contains the poisonous status of each mushroom with two possible values, “p” for “poisonous” and “e” for edible, it will serve as the clustering we seek to recover.
| edibility | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | V10 |
|---|---|---|---|---|---|---|---|---|---|
| p | x | s | n | t | p | f | c | n | k |
| e | x | s | y | t | a | f | c | b | k |
| e | b | s | w | t | l | f | c | b | n |
| p | x | y | w | t | p | f | c | n | n |
| e | x | s | g | f | n | f | w | b | k |
| e | x | y | y | t | a | f | c | b | n |
The remaining variables are used for clustering. Note that we only use a subset of the data for illustration purpose here.
Clustering
The clustering is done via the main function greed()
with argument model set to LCA and the genetic hybrid
algorithm for ICL maximization.
Note: The
Lcamodel may only be used with datasets stored in a data.frame object containing factors only. When such data are provided to thegreed()function, anLcamodel is picked by default. To perform the clustering, it is therefore sufficient to call greed with the prepared data.frame.
sol_mush<-greed(X[subset,], model=Lca())
#>
#> ── Fitting a LCA model ──
#>
#> ℹ Initializing a population of 20 solutions.
#> ℹ Generation 1 : best solution with an ICL of -12697 and 13 clusters.
#> ℹ Generation 2 : best solution with an ICL of -12620 and 13 clusters.
#> ℹ Generation 3 : best solution with an ICL of -12612 and 14 clusters.
#> ℹ Generation 4 : best solution with an ICL of -12612 and 14 clusters.
#> ── Final clustering ──
#>
#> ── Clustering with a LCA model 13 clusters and an ICL of -12586The hybrid genetic algorithm found a solution with \(K=13\) clusters which is quite over-segmented. But, it display a good separation among edible and poisonous mushrooms:
table(label, clustering(sol_mush)) %>% knitr::kable()| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| e | 221 | 7 | 11 | 74 | 0 | 92 | 27 | 32 | 6 | 21 | 11 | 0 | 0 |
| p | 0 | 21 | 37 | 0 | 46 | 0 | 0 | 0 | 9 | 0 | 3 | 209 | 173 |
Partition’s NMI is 0.29 which is explained by the over-segmentation of the solution compared to the \(2\)-class problem.
Analysis of the hierarchy
Exploring the dendrogram provided by the hierarchical algorithm is quite useful in this case.
plot(sol_mush, type='tree')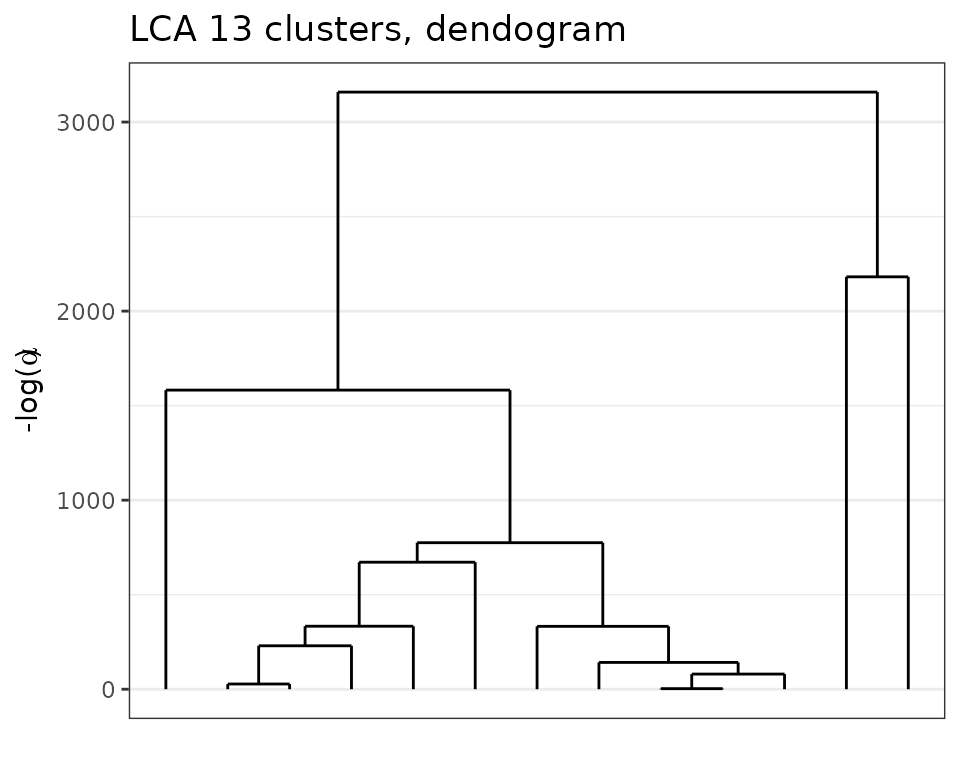
Dendogram obtained with greed with the Lca model on the Mushroom dataset.
We clearly see a hierarchical structure appearing with \(K=2\) or \(K=4\) main clusters. Thus, we can cut the tree at this height and look at the solution.
sol2 = cut(sol_mush, 2)
table(label, clustering(sol2)) %>% knitr::kable()| 1 | 2 | |
|---|---|---|
| e | 502 | 0 |
| p | 116 | 382 |
Here, we clearly see that the order of merges is consistent with the labels, and the final ARI is 0.57. While, some poisonous mushrooms have been categorized as edible, this is the consequence of the way the labels have been set, since mushrooms for which the edibility status was unknown were classified as poisonous by default. While this choice is reasonable from a strict health perspective. Furthermore, as the data documentation specifies, ’‘’’. Thus, the unsupervised problem is hard and the obtained clustering is already satisfactory. Moreover, this illustrates the interest of having the hierarchical algorithm in order to access coarser partitions.
Young people survey data
data("Youngpeoplesurvey")Data preparation
We begin by preprocessing the data, only keeping the categorical variable. The original dataset has \(n=1010\) respondents for \(p=19\). We keep only the feature related to the musical taste of the respondent and remove potential strike of identical responses. Eventually, the data are cast to factors with an explicit levels for the missing responses.
Hierarchical clustering
As previously the clustering is obtained with a call to greed and the Lca generative model will be taken by default since the dataset is a data.frame with factors only. We demonstrate here how to increase a little bit the exploration capabilities of the optimization algorithm by increasing the population size and the probability of mutation.
sol=greed(X, alg = Hybrid(pop_size = 50,prob_mutation = 0.5))
#>
#> ── Fitting a LCA model ──
#>
#> ℹ Initializing a population of 50 solutions.
#> ℹ Generation 1 : best solution with an ICL of -27727 and 14 clusters.
#> ℹ Generation 2 : best solution with an ICL of -27635 and 11 clusters.
#> ℹ Generation 3 : best solution with an ICL of -27511 and 9 clusters.
#> ℹ Generation 4 : best solution with an ICL of -27449 and 8 clusters.
#> ℹ Generation 5 : best solution with an ICL of -27410 and 7 clusters.
#> ℹ Generation 6 : best solution with an ICL of -27410 and 7 clusters.
#> ── Final clustering ──
#>
#> ── Clustering with a LCA model 6 clusters and an ICL of -27406The algorithm found \(K=6\) clusters which are quite balanced. To explore the results, we plot the dendogram found.
plot(sol,type='tree')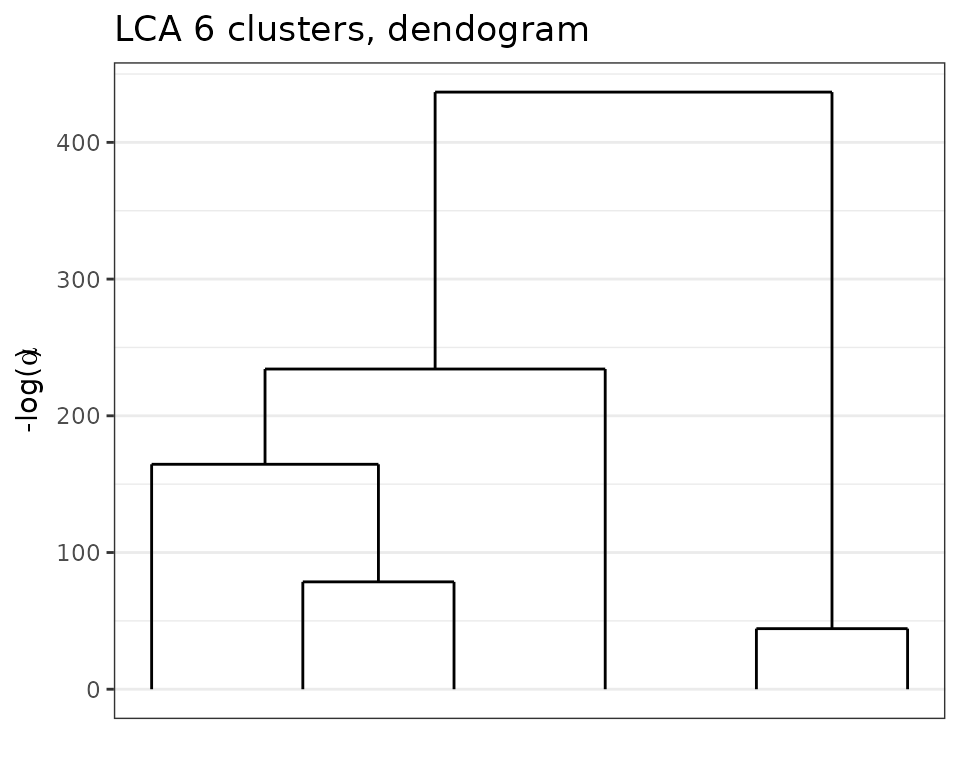
Dendogram obtained with greed with the Lca model on the Young people survey dataset.
Clustering analysis
We may also used the marginals plot to depict the
conditional probabilities of the different responses knowing the
clusters assignment.
plot(sol,type='marginals')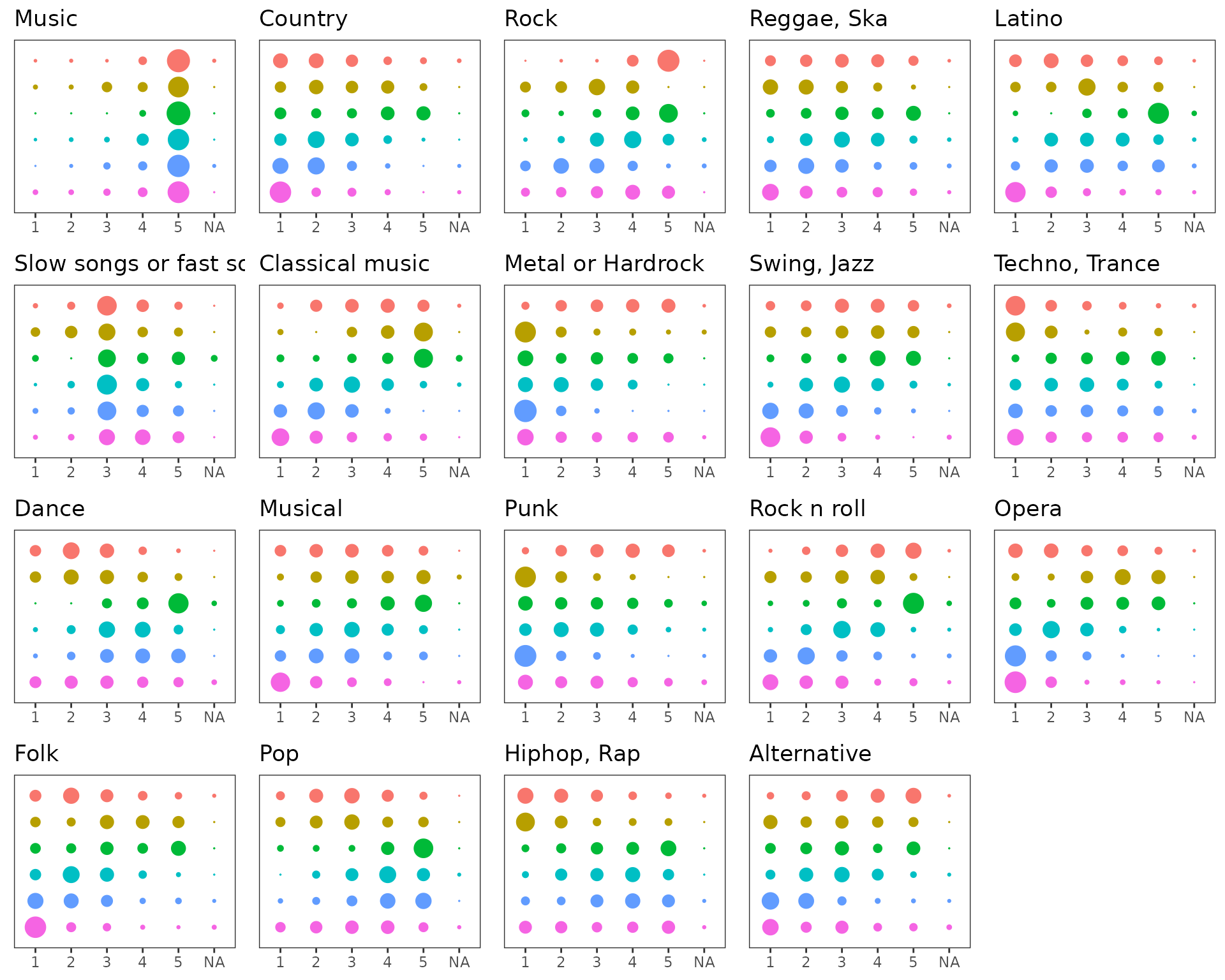
Marginals plot of the clustering obtained with greed on the Young adult data.
The clusters appear to be quite different and coherent. For example, the seventh group (second row, in brown) display a strong tendency to like Opera and Classical music and dislike more modern genres (Techno, Trance, Punk or Hi-Hop), whereas the 4th group (top row, in pink) corresponds to music lovers with quite eclectic musical taste across the proposed survey’s genres.
In addition, the conditional maximum a posteriori estimates of \(\theta_{kj}\) are available through the
coef() method.
params = coef(sol)And look for example at the cluster distributions for the Country music style:
| 1 | 2 | 3 | 4 | 5 | NA | |
|---|---|---|---|---|---|---|
| cluster1 | 0.33 | 0.33 | 0.21 | 0.08 | 0.04 | 0.01 |
| cluster2 | 0.17 | 0.31 | 0.22 | 0.25 | 0.06 | 0.00 |
| cluster3 | 0.19 | 0.12 | 0.12 | 0.27 | 0.29 | 0.00 |
| cluster4 | 0.21 | 0.44 | 0.26 | 0.08 | 0.01 | 0.00 |
| cluster5 | 0.39 | 0.46 | 0.12 | 0.02 | 0.00 | 0.01 |
| cluster6 | 0.77 | 0.11 | 0.09 | 0.03 | 0.00 | 0.01 |
Cluster structures may also be visualized with a word clouds of feature names. In this representation, a color encodes if the feature has an average score greater than the average score of the whole population. A big blue feature corresponds to music type that scores higher than the mean in this cluster and big red feature to music type that have a smaller score than the mean in the corresponding group.
# get the Lca MAP parameters estimates
params = coef(sol)
# compute the mean score per cluster and features
means_scores = lapply(params$Thetak,function(x){
apply(x[,1:5],1,function(r){
sum(r*1:5)
})
})
# move to long format
means_scores_long = do.call(rbind,
map2(means_scores, names(means_scores),function(x,y){
tibble(cluster=1:K(sol),mean=x,var=y)
})) %>%
mutate(var = gsub("\\."," ",var))
# compute the average score for the whole population
means_scores_glob = Xnum %>%
summarise_all(function(x){mean(x,na.rm=TRUE)}) %>%
tidyr::pivot_longer(all_of(1:ncol(Xnum)),names_to = "var",) %>%
mutate(var = gsub("[,-/]"," ",var))
# compute the differences between clusters scores and averages scores
gg = means_scores_long %>%
left_join(means_scores_glob) %>%
mutate(dm=mean-value)
#> Joining, by = "var"
# create the word clouds (we kept only the music genre that depart from the average for each cluster)
ggplot(gg %>% filter(abs(dm)>0.1), aes(label = var, size = abs(dm),color=dm)) +
geom_text_wordcloud() +
scale_size_area(max_size = 7) +
theme_minimal() +
scale_color_gradient2(guide="none")+
facet_wrap(~cluster)
Word cloud visualization of the greed clustering on the Young adult survey data.
Using such a visualization allow to easily describe the different groups. The first cluster almost exclusively likes Pop and Dance music, the second Opera and Classical music. The third cluster has higher score for almost all music genres and the third is close to the global average score and so on.